gs_ddr
背景信息
为了简化手动部署及使用资源池化双集群[网络双集群|dorado存储双集群]的过程,为用户提供更加简单快捷的使用体验,openGauss提供了gs_ddr工具。
该工具可完成自动化容灾搭建、容灾升主、计划内主备切换、容灾解除、容灾状态监控功能、显示帮助信息和显示版本号信息等功能。
约束条件
- 搭建容灾的两个集群必须是具备
cm工具的集群。 - 搭建容灾的主备集群版本号必须相同。
- 容灾双集群搭建前不支持已存在级联备。
- 搭建容灾的两个集群的初始数据库用户及密码必须相同,所有指令需在数据库用户下执行;
- 如果搭建容灾的两个集群存在数据不一致情况,在进行容灾搭建命令执行时,会对灾备集群进行全量
build完成初始化,搭建前请确认清楚。 - 容灾搭建指令、计划内主备切换指令执行,需要同时在主备集群(执行节点:集群内主备节点均可)执行对应指令。因为主备集群执行过程会进行交互等待。
- 搭建容灾关系前,主集群需创建容灾用户,用于容灾鉴权,主备集群必须使用相同的容灾用户名和密码,一次容灾搭建后,该用户密码不可修改。若需修改容灾用户名与密码,需要解除容灾,使用新的容灾用户重新进行搭建。容灾用户密码中不可包含以下字符“| ;&$<>`'"{}()[]~*?!\n-空白”。
- 搭建容灾关系时,如果集群副本数<=2,会设置
most_available_sync为on,在容灾解除或者failover后此参数不会恢复初始值,持续保证集群为最大可用模式。 - 搭建容灾关系时,会设置
synchronous_commit为on,解除容灾或failover升主时恢复初始值。灾备集群可读不可写。 - 灾备集群通过
failover命令升主后,和原主集群灾备关系将失效,需要重新搭建容灾关系。 - 灾备集群
DN多数派故障或者CMS、DN全故障,无法启动容灾,灾备集群无法升主,无法作为灾备集群,需要重建灾备集群。 - 主集群如果进行了强切操作,需要重建灾备集群。
- 主备集群都支持
gs_probackup工具中全量备份和增量备份。 - 容灾关系搭建之后,不支持
DN实例端口修改。 - 建立容灾关系的主数据库实例与灾备数据库实例之间不支持
GUC参数的同步。 - 主备集群不支持节点替换、修复、升降副本,
DCF模式。 - 当灾备数据库实例为2副本时,灾备数据库实例在1个副本损坏时,仍可以升主对外提供服务,如果剩余的这个副本也损坏,将导致不可避免的数据丢失。
- 容灾状态下暂不支持升级,需解除容灾关系后分别升级主备集群再重新进行搭建双集群。
- 建议对于容灾双集群流复制
IP的选择,应考虑尽量使集群内的网络平面与跨集群网络平面分离,便于压力分流并提高安全性。 - 升级过程中不支持容灾搭建、主备切换、容灾升主、容灾查询、容灾解除操作。
- 需以操作系统用户
omm执行gs_ddr命令。
预置条件
- 预先搭建好两个资源池化单集群;
- 两个资源池化单集群的用户相同。
语法
容灾搭建
gs_ddr -t start -m [primary|disaster_standby] --disaster_type [dorado|stream] [-X XMLFILE] [--json JSONFILE] [--time-out=SECS] [-l LOGFILE]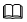 start命令说明:
start命令说明:该命令需在主集群、备集群上均执行一次;
--disaster_type参数其默认值为dorado,只需要在容灾搭建时指定,后续指令中不需要再指定计划外容灾升主
gs_ddr -t failover [-l LOGFILE] failover命令说明:注意:该命令只能在备集群的首备节点执行,且执行后容灾关系被解除。使用场景共有两种,如下:
一是主集群异常(被摧毁、宕机等),需要备集群脱离容灾状态,对外提供服务;
二是容灾关系被拆除,备集群需要脱离容灾状态恢复为正常的单集群
计划内主备切换
gs_ddr -t switchover -m [primary|disaster_standby] [--time-out=SECS] [-l LOGFILE] switchover命令说明:该命令需在主集群、备集群上各执行一次,主降备,备升主。
容灾解除
gs_ddr -t stop [-X XMLFILE] [--json JSONFILE] [-l LOGFILE] stop命令说明:该命令只能在主集群的首节点执行且执行之后,容灾关系会被拆除,此时使用
gs_ddr -t query命令查询主集群状态为Normal,表示主集群已恢复为正常的单集群;备集群要脱离容灾状态,还需要在首备节点执行
gs_ddr -t failover命令,让备集群脱离容灾状态。容灾状态监控
gs_ddr -t query [-l LOGFILE] query命令说明:该命令可以在双集群的任意节点上执行,用于状态或任务进度查询。
参数说明
gs_ddr参数可以分为如下几类:
通用参数:
-t
gs_ddr命令的任务类型。取值范围:start、failover、switchover、stop、query。
-l
指定日志文件及存放路径。
默认值:
$GAUSSLOG/om/gs_ddr-YYYY-MM-DD_hhmmss.log-?, --help
显示帮助信息。
-V, --version
显示版本号信息。
搭建容灾参数:
-m
期望该集群在容灾关系中成为的角色
取值范围:
primary(主集群)或disaster_standby(灾备集群)-X
集群安装时的
xml,xml中也可以配置容灾信息用于容灾搭建,即在安装xml的基础上扩展三个字段(localStreamIpmap1、remoteStreamIpmap1、remotedataPortBase)新增字段的配置方式如下:
<!-- 每台服务器上的节点部署信息 --> <DEVICELIST> <DEVICE sn="pekpomdev00038"> <!-- 当前主机上需要部署的主DN个数 --> <PARAM name="dataNum" value="1"/> <!-- 主DN的基础端口号 --> <PARAM name="dataPortBase" value="26000"/> <!-- 本集群dn分片各节点用于SSH可信通道的IP与流复制的IP映射关系 --> <PARAM name="localStreamIpmap1" value="(10.244.44.216,172.31.12.58),(10.244.45.120,172.31.0.91)"/> <!-- 对端集群dn分片各节点用于SSH可信通道的IP与流复制的IP映射关系 --> <PARAM name="remoteStreamIpmap1" value="(10.244.45.144,172.31.2.200),(10.244.45.40,172.31.0.38),(10.244.46.138,172.31.11.145),(10.244.48.60,172.31.9.37),(10.244.47.240,172.31.11.125)"/> <!-- 对端集群的主dn端口号 --> <PARAM name="remotedataPortBase" value="26000"/> </DEVICE> xml文件参数配置说明:在
localStreamIpmap1及remoteStreamIpmap1中,SSH可信通道IP即可信的(安全的)外网IP;流复制IP即用于主备复制的IP。若无外网IP,可将其配置为流复制IP。以
localStreamIpmap1为例,介绍配置IP映射的方法:在localStreamIpmap1参数的value中,有两个小括号,表明该集群规模是两节点的,在每个小括号中,显示的IP映射是这样的(SSH可信通道IP,流式复制IP),即为两个IP之间的映射关系。remotedataPortBase为对端集群的主dn端口号。--json
带有容灾信息的
json文件。json文件的配置方式如下:{ "remoteClusterConf": { "port": 26000, "shards": [[ {"ip": "10.244.45.144", "dataIp": "172.31.2.200"}, {"ip": "10.244.45.40", "dataIp": "172.31.0.38"}, {"ip": "10.244.46.138", "dataIp": "172.31.11.145"}, {"ip": "10.244.48.60", "dataIp": "172.31.9.37"}, {"ip": "10.244.47.240", "dataIp": "172.31.11.125"} ]] }, "localClusterConf": { "port": 26000, "shards": [[ {"ip": "10.244.44.216", "dataIp": "172.31.12.58"}, {"ip": "10.244.45.120", "dataIp": "172.31.0.91"} ]] } } json文件参数配置说明:remoteClusterConf为对端集群的dn分片信息,其中port为对端集群主dn的端口。localClusterConf为本集群的dn分片信息,其中port为本集群主dn的端口。shards中的IP为SSH可信通道IP,即可信的(安全的)外网IP;流复制IP,即用于主备复制的IP。若无外网IP,可将其配置为流复制IP。注意:
-X与--json参数支持二选一方式进行配置容灾信息,如果命令行中两个参数全部下发,则以json为准。--time-out=SECS
指定超时时间,主集群会等待备集群连接的超时时间,超时则判定失败,
om脚本自动退出。单位:s。取值范围:正整数,建议值1200。
默认值:1200
说明:需要注意的是,
build和start集群都有自己的超时时间设置。对于build集群,默认的超时时间为1209600秒(14天),如果在这个时间内没有完成构建操作,将自动退出。而对于
start集群,默认的超时时间为604800秒(一周),即一周内如果没有完成启动操作,将自动退出。如果不指定--time-out=SECS参数,那么在build集群中,超时时间为1200秒后不会自动退出;而在start集群中,超时时间为1200秒后也不会自动退出。--disaster_type
搭建时用于指定双集群类型。其默认值为
dorado,在start命令中若不指定该参数,默认搭建资源池化存储复制双集群。-f
容灾搭建时,强制移除
start命令生成的临时标志文件,让搭建流程从头执行,而不是从上次中断的位置继续执行。
容灾解除参数:
-X
集群安装时的xml,需要额外配置容灾信息,即扩展三个字段(“localStreamIpmap1”、“remoteStreamIpmap1”、“remotedataPortBase”)
--json
带有本端及对端容灾信息的json文件。
说明:-X、--json的配置方式请参考本节容灾搭建参数配置。
容灾查询参数:
- 无
容灾状态查询结果说明如下:
示例1. 资源池化dorado存储双集群
特别说明:使用gs_ddr工具搭建或操作dorado存储双集群时,需要与Dorado控制平台DeviceManger进行交互,具体的交互方式将插入到各个功能的示例中。
主集群搭建容灾关系。
gs_ddr -t start -m primary --json /usr4/og_sf_ff/dc.json -------------------------------------------------------------------------------- Dorado disaster recovery start 09cb445ee6d311ef897e78b46a3ff63e -------------------------------------------------------------------------------- Start create dorado storage disaster relationship. param.stage = None. Got the step for action:[start]. Successfully check cluster status is: Normal. Successfully check instance status. Start set ss_disaster_mode Start update pg_hba config. Starting set application_name param Successfully set application_name param. Stopping the cluster. Successfully stopped the cluster. Start set all dss instance STORAGE_MODE. Successfully set dss cfg STORAGE_MODE to CLUSTER_RAID. Starting the cluster. Successfully started primary instance. Please wait for standby instances. Waiting cluster normal. Successfully started standby instances. Successfully set ss_double_cluster_mode Successfully set cm_guc. Please ensure that the "Remote Replication Pairs" configured correctly between the primary cluster and the disaster recovery cluster, with Replication Mode in "Synchronous" state. Ready to move on (yes/no)? yes Waiting for the main standby connection. And now, on the standby cluster exectue the command: gs_ddr -t start -m disaster_standby [-X /path/of/xml | --json /path/of/json] --disaster_type [dorado|stream] Main standby already connected. Successfully check cluster status is: Normal. Successfully removed step file. Successfully do dorado disaster recovery start.备集群搭建容灾关系。
gs_ddr -t start -m disaster_standby --json /usr4/og_sf_ff/dc.json -------------------------------------------------------------------------------- Dorado disaster recovery start 0ce99a28e6d311efa82ef82e3f372fc4 -------------------------------------------------------------------------------- Start create dorado storage disaster relationship. param.stage = None. Got the step for action:[start]. Successfully check cluster status is: Normal. Successfully check instance status. Start set ss_disaster_mode Start update pg_hba config. Starting set application_name param Successfully set application_name param. Stopping the cluster. Successfully stopped the cluster. Start set all dss instance STORAGE_MODE. Successfully set dss cfg STORAGE_MODE to CLUSTER_RAID. Successfully set ss_double_cluster_mode Start start dssserver in main standby node. Successfully Start dssserver on node [openGauss79] Start build main standby datanode in disaster standby cluster. And now, on the primary cluster exectue the command: gs_ddr -t start -m primary [-X /path/of/xml | --json /path/of/json] --disaster_type [dorado|stream] Successfully build main standby in disaster standby cluster on node [openGauss79] Stop dssserver instance on main standby node. Successfully stop dssserver before start cluster on node [openGauss79] Start set all dss instance STORAGE_MODE. Successfully set dss cfg STORAGE_MODE to CLUSTER_RAID. Start set all dss instance CLUSTER_RUN_MODE. Successfully set dss cfg CLUSTER_RUN_MODE to cluster_standby. Successfully set cm_guc. Please ensure that the "Remote Replication Pairs" configured correctly between the primary cluster and the disaster recovery cluster, with Replication Mode in "Synchronous" state. Ready to move on (yes/no)? yes Starting the cluster. Successfully started primary instance. Please wait for standby instances. Waiting cluster normal. Successfully started standby instances. Successfully check cluster status is: Normal. Successfully removed step file. Successfully do dorado disaster recovery start.注意:待主集群及备集群均出现
Ready to move on (yes/no)?时,在DeviceManager上,做如下操作:找到【数据保护】 -> 【lun】 -> 【远程复制pair】,找到自己的盘,双击进入
UI界面,检查【本端资源】与【远端资源】之间的同步方向及UI面板的从资源保护状态为可读写。以上步骤完成后,点击右上角【操作】,选择【启用从资源保护】,此时从资源保护状态为只读,再次点击【操作】,选择【同步】,待【本端资源】与【远端资源】之间出现
正常字样时,回到环境中,分别在主集群,备集群上输入
yes,等待搭建完成即可。计划内主集群降备。
gs_ddr -t switchover -m disaster_standby -------------------------------------------------------------------------------- Dorado disaster recovery switchover fba8f95ee6d511efa2bc78b46a3ff63e -------------------------------------------------------------------------------- Start dorado disaster switchover. Parse cluster conf from file. Successfully parse cluster conf from file. Successfully get the para disaster_type: dorado. And now, on the disaster_standby cluster exectue the command: gs_ddr -t switchover -m primary Got the step for action:[switchover]. Waiting for cluster and all instances normal. Stopping the cluster. Successfully stopped the cluster. Successfully do_first_stage_for_switchover. Please manually switchover the primary and secondary replication relationship of the "Remote Replication Pairs" in Device Manager, and ensure the "Local Resource Role" is Secondary.Ready to move on (yes/no)? yes Start set all dss instance CLUSTER_RUN_MODE. Successfully set dss cfg CLUSTER_RUN_MODE to cluster_standby. Starting the cluster. Successfully started primary instance. Please wait for standby instances. Waiting cluster normal. Successfully started standby instances. The cluster status is Normal. Successfully removed step file. Successfully do dorado disaster recovery switchover.计划内备集群升主。
gs_ddr -t switchover -m primary -------------------------------------------------------------------------------- Dorado disaster recovery switchover 0010eb1ee6d611efae78f82e3f372fc4 -------------------------------------------------------------------------------- Start dorado disaster switchover. Parse cluster conf from file. Successfully parse cluster conf from file. Successfully get the para disaster_type: dorado. And now, on the primary cluster exectue the command: gs_ddr -t switchover -m disaster_standby Got the step for action:[switchover]. Waiting for cluster and all instances normal. Successfully do_first_stage_for_switchover. Please ensure that the "Remote Replication Pairs" configured correctly, and check the "Local Resource Role" is Primary.Ready to move on (yes/no)? yes Start reload cm_agent and cm_server param. Successfully reload cm guc param on all nodes. Start set all dss instance CLUSTER_RUN_MODE. Successfully set dss cfg CLUSTER_RUN_MODE to cluster_primary. Start failover main standby datanode in disaster standby cluster. Successfully Failover main standby in disaster standby cluster on node [openGauss79] Waiting cluster normal. Successfully started datanode instances. Waiting for the main standby connection. Main standby already connected. Successfully removed step file. Successfully do dorado disaster recovery switchover.注意:待主集群及备集群均出现
Ready to move on (yes/no)?时,在DeviceManager上,做如下操作:找到【数据保护】 -> 【lun】 -> 【远程复制pair】,找到自己的盘,双击进入
UI界面。点击右上角【操作】,选择【主从切换】并确认,之后回到环境中,分别在主集群,备集群上输入
yes,等待主备集群切换完成即可。灾备集群容灾升主。
gs_ddr -t failover -------------------------------------------------------------------------------- Dorado disaster recovery failover 5078895ce6d811ef859678b46a3ff63e -------------------------------------------------------------------------------- Start dorado disaster recovery failover. Got the step for action:[failover]. Successfully check cluster status is: Normal. Parse cluster conf from file. Successfully parse cluster conf from file. Successfully get the para disaster_type: dorado. Successfully do_first_stage_for_switchover. Please ensure that the "Remote Replication Pairs" configured correctly, and check the "Local Resource Role" is Primary.Ready to move on (yes/no)? yes Start reload cm_agent and cm_server param. Successfully reload cm guc param on all nodes. Start set all dss instance CLUSTER_RUN_MODE. Successfully set dss cfg CLUSTER_RUN_MODE to cluster_primary. Start failover main standby datanode in disaster standby cluster. Successfully Failover main standby in disaster standby cluster on node [openGauss115] Waiting cluster normal. Successfully started datanode instances. Successfully removed step file. Finished remove streaming dir. Successfully do dorado disaster recovery failover.注意:待主集群出现
Ready to move on (yes/no)?时,在DeviceManager上,做如下操作:找到【数据保护】 -> 【lun】 -> 【远程复制pair】,找到自己的盘,双击进入
UI界面。点击右上角【操作】,选择【分裂】并确认,再次点击【操作】,选择【取消从资源保护】,此时
UI界面的从资源保护状态为可读写。之后回到环境中,在备集群上输入yes,等待灾备升主完成即可。主集群容灾解除。
gs_ddr -t stop --json /usr4/og_sf_ff/dc.json -------------------------------------------------------------------------------- Dorado disaster recovery stop f0308324e6d711efa0f9f82e3f372fc4 -------------------------------------------------------------------------------- Start remove dorado disaster recovery relationship. Got the step for action:[stop]. Successfully check cluster status is: Normal. Check cluster type succeed. Starting remove all node dn instances repl infos. Successfully remove all node dn instances repl infos. Start remove pg_hba config. Finished remove pg_hba config. Start remove cluster file. Finished remove cluster file. Successfully check cluster status is: Normal. Finished remove streaming dir. Successfully do dorado disaster recovery stop.查询容灾状态。
gs_ddr -t query -------------------------------------------------------------------------------- Dorado disaster recovery query 6650b2ece6d611ef8cb278b46a3ffcce -------------------------------------------------------------------------------- Start dorado disaster query. Start check archive. Start check recovery. Successfully executed dorado disaster recovery query, result: {'ddr_cluster_stat': 'recovery', 'ddr_failover_stat': '', 'ddr_switchover_stat': ''}
示例2. 资源池化网络双集群
主集群搭建容灾关系。
gs_ddr -t start -m primary --disaster_type stream -X /usr1/og_sf_bot/11.xml -------------------------------------------------------------------------------- Dorado disaster recovery start e3e94128062611f0aae378b46a3ff63e -------------------------------------------------------------------------------- Start create dorado storage disaster relationship. param.stage = None. Got the step for action:[start]. Successfully check cluster status is: Normal. Successfully check instance status. Start set ss_disaster_mode Start update pg_hba config. Starting set application_name param Successfully set application_name param. Stopping the cluster. Successfully stopped the cluster. Starting the cluster. Successfully started primary instance. Please wait for standby instances. Waiting cluster normal. Successfully started standby instances. Successfully set ss_double_cluster_mode Successfully set cm_guc. Waiting for the main standby connection. And now, on the standby cluster exectue the command: gs_ddr -t start -m disaster_standby [-X /path/of/xml | --json /path/of/json] --disaster_type [dorado|stream] Main standby already connected. Successfully check cluster status is: Normal. Successfully removed step file. Successfully do dorado disaster recovery start.备集群搭建容灾关系。
gs_ddr -t start -m disaster_standby --disaster_type stream -X /usr1/og_sf_bot/11.xml -------------------------------------------------------------------------------- Dorado disaster recovery start e4cc4810062611f0bba5f82e3f372fc4 -------------------------------------------------------------------------------- Start create dorado storage disaster relationship. param.stage = None. Got the step for action:[start]. Successfully check cluster status is: Normal. Successfully check instance status. Start set ss_disaster_mode Start update pg_hba config. Starting set application_name param Successfully set application_name param. Stopping the cluster. Successfully stopped the cluster. Successfully set ss_double_cluster_mode Start dssserver in main standby node. Successfully Start dssserver on node [openGauss79] Start build main standby datanode in disaster standby cluster. And now, on the primary cluster exectue the command: gs_ddr -t start -m primary [-X /path/of/xml | --json /path/of/json] --disaster_type [dorado|stream] Successfully build main standby in disaster standby cluster on node [openGauss79] Stop dssserver instance on main standby node. Successfully stop dssserver before start cluster on node [openGauss79] Successfully set cm_guc. Starting the cluster. Successfully started primary instance. Please wait for standby instances. Waiting cluster normal. Successfully started standby instances. Successfully check cluster status is: Normal. Successfully removed step file. Successfully do dorado disaster recovery start.计划内主集群降备。
gs_ddr -t switchover -m disaster_standby -------------------------------------------------------------------------------- Dorado disaster recovery switchover 0bf72e54062811f0be3a78b46a3ff63e -------------------------------------------------------------------------------- Start dorado disaster switchover. Parse cluster conf from file. Successfully parse cluster conf from file. Successfully get the para disaster_type: stream. And now, on the disaster_standby cluster exectue the command: gs_ddr -t switchover -m primary Got the step for action:[switchover]. Waiting for cluster and all instances normal. Stopping the cluster. Successfully stopped the cluster. Successfully do_first_stage_for_switchover. Starting the cluster. Successfully started primary instance. Please wait for standby instances. Waiting cluster normal. Successfully started standby instances. The cluster status is Normal. Successfully removed step file. Successfully do dorado disaster recovery switchover.计划内备集群升主。
gs_ddr -t switchover -m primary -------------------------------------------------------------------------------- Dorado disaster recovery switchover 0cb56a2c062811f09579f82e3f372fc4 -------------------------------------------------------------------------------- Start dorado disaster switchover. Parse cluster conf from file. Successfully parse cluster conf from file. Successfully get the para disaster_type: stream. And now, on the primary cluster exectue the command: gs_ddr -t switchover -m disaster_standby Got the step for action:[switchover]. Waiting for cluster and all instances normal. Successfully do_first_stage_for_switchover. Start reload cm_agent and cm_server param. Successfully reload cm guc param on all nodes. Start set all dss instance CLUSTER_RUN_MODE. Successfully set dss cfg CLUSTER_RUN_MODE to cluster_primary. Start failover main standby datanode in disaster standby cluster. Successfully Failover main standby in disaster standby cluster on node [openGauss79] Waiting cluster normal. Successfully started datanode instances. Waiting for the main standby connection. Main standby already connected. Successfully removed step file. Successfully do dorado disaster recovery switchover.灾备集群容灾升主。
gs_ddr -t failover -------------------------------------------------------------------------------- Dorado disaster recovery failover 5a38ee1c062911f0885078b46a3ff63e -------------------------------------------------------------------------------- Start dorado disaster recovery failover. Got the step for action:[failover]. Successfully check cluster status is: Normal. Parse cluster conf from file. Successfully parse cluster conf from file. Successfully get the para disaster_type: stream. Successfully do_first_stage_for_switchover. Start reload cm_agent and cm_server param. Successfully reload cm guc param on all nodes. Start set all dss instance CLUSTER_RUN_MODE. Successfully set dss cfg CLUSTER_RUN_MODE to cluster_primary. Start failover main standby datanode in disaster standby cluster. Successfully Failover main standby in disaster standby cluster on node [openGauss115] Waiting cluster normal. Successfully started datanode instances. Successfully removed step file. Finished remove streaming dir. Successfully do dorado disaster recovery failover.主集群容灾解除。
gs_ddr -t stop -X /usr1/og_sf_bot/11.xml -------------------------------------------------------------------------------- Dorado disaster recovery stop f0f5a698062811f0bb4ef82e3f372fc4 -------------------------------------------------------------------------------- Start remove dorado disaster recovery relationship. Got the step for action:[stop]. Successfully check cluster status is: Normal. Check cluster type succeed. Starting remove all node dn instances repl infos. Successfully remove all node dn instances repl infos. Start remove pg_hba config. Finished remove pg_hba config. Start remove cluster file. Finished remove cluster file. Successfully check cluster status is: Normal. Finished remove streaming dir. Successfully do dorado disaster recovery stop.查询容灾状态。
gs_ddr -t query -------------------------------------------------------------------------------- Dorado disaster recovery query a4a30d52062911f0a1f378b46a3ffcce -------------------------------------------------------------------------------- Start dorado disaster query. Start check archive. Start check recovery. Successfully executed dorado disaster recovery query, result: {'ddr_cluster_stat': 'normal', 'ddr_failover_stat': '', 'ddr_switchover_stat': ''}