规划存储模型
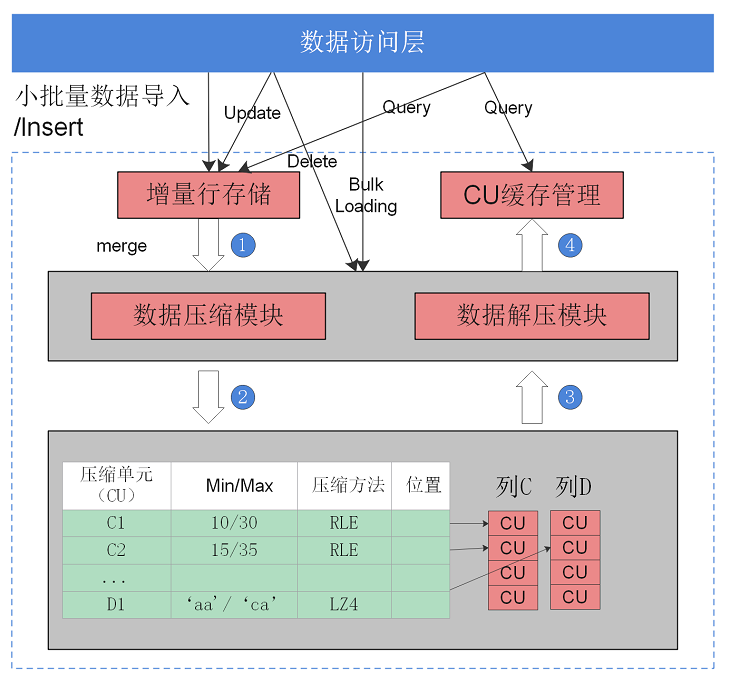
可获得性
openGauss支持行列混合存储,此特性自openGauss 1.0.0版本开始引入。
特性简介
openGauss支持行存储和列存储两种存储模型,用户可以根据具体的使用场景,建表时选择行存储还是列存储表。
一般情况下,如果表的字段比较多(即大宽表),查询中涉及到列不很多的情况下,适合列存储。列存储方式如图1所示。如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。
客户价值
在大宽表、数据量比较大的场景中,查询经常关注某些列,行存储引擎查询性能比较差。例如,气象局的场景,单表有200~800个列,查询经常访问10个列,在类似这样的场景下,向量化执行技术和列存储引擎可以极大的提升性能和减少存储空间。
特性描述
表有行存表和列存表两种存储模型。两种存储模型各有优劣,建议根据实际情况选择。通常openGauss用于OLTP(联机事务处理)场景的数据库,默认使用行存储,仅对执行复杂查询且数据量大的OLAP(联机分析处理)场景时,才使用列存储。
行存表
默认创建表的类型。数据按行进行存储,即一行数据紧挨着存储。行存表支持完整的增删改查。适用于对数据需要经常更新的场景。
列存表
数据按列进行存储,即一列所有数据紧挨着存储。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询,insert插入单条记录性能差。
行存储是指将表按行存储到硬盘分区上,列存储是指将表按列存储到硬盘分区上。默认情况下,创建的表为行存储。行存储和列存储的差异请参见图1。
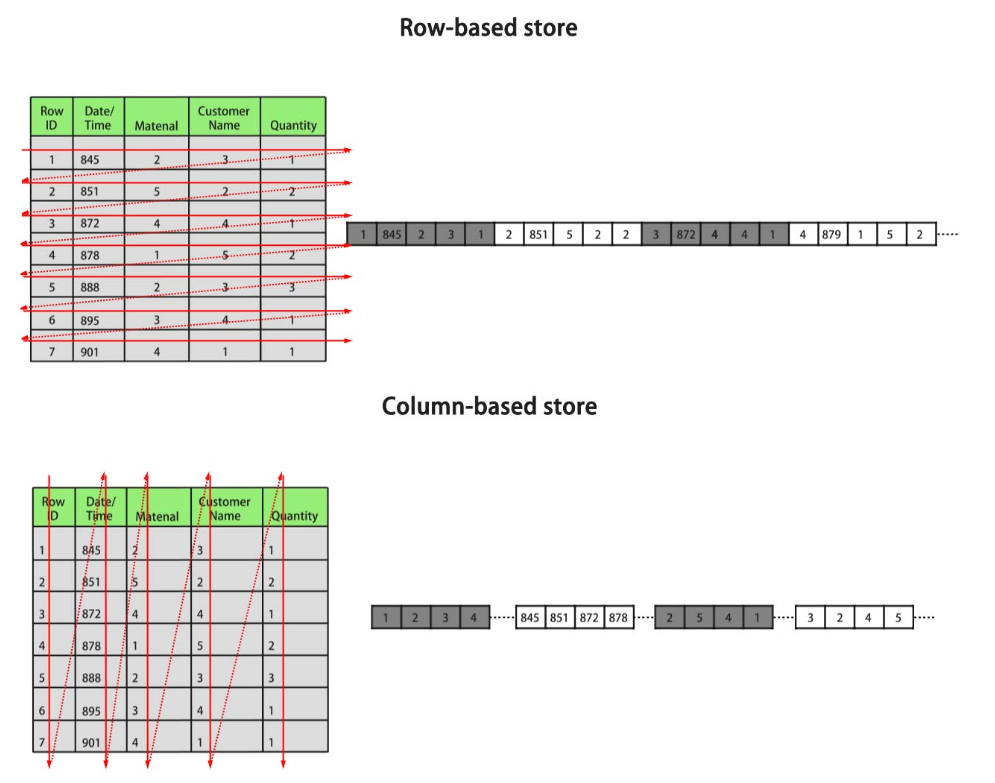
上图中,左上为行存表,右上为行存表在硬盘上的存储方式。左下为列存表,右下为列存表在硬盘上的存储方式。
行、列存储有如下优缺点:
|
|
一般情况下,如果表的字段比较多(大宽表),查询中涉及到的列不多的情况下,适合列存储。如果表的字段个数比较少,查询大部分字段,那么选择行存储比较好。
| |
|
特性约束
列存的规格约束如下:
表
- 不支持全局临时表。
- 不支持继承表。
- 不支持create table of typename。
- 不支持二级分区。
- 列存仅支持范围分区。
- 支持的分布表类型:REPLICATION分布、RANGE分布、LIST分布、HASH分布。
索引
- 支持索引的类型:psort、btree、gin。
SQL语法
- insert/update/delete returning语句不支持。
- rownum、start with connect by采用了转换成行存支持实现。
存储过程
- 列存cursor不支持BACKWARD、PRIOR等涉及反向获取操作。
数据类型。支持以下基础类型及对应的数组类型:
- 数值类型:TINYINT SMALLINT INTEGER BIGINT OID REAL DOUBLE NUMERIC。
- 布尔类型:BOOLEAN。
- 字符类型:CHAR(n) VARCHAR(n) NVARCHAR2(n) TEXT CLOB。
- 日期/时间类型:DATE TIME TIMESTAMP SMALLDATETIME INTERVAL tinterval reltime abstime。
- 网络地址类型:CIDR INET。
- 货币类型:MONEY。
- 位串类型:BIT(n) BIT VARYING(n)。
- HLL数据类型:HLL HLL_HASHVAL。
- 二进制类型:BYTEA BYTEAWITHOUTORDERCOL BYTEAWITHOUTORDERWITHEQUALCOL。
- 其他类型(包括自定义类型)均不支持。
存储&事务
- 不支持闪回。
- 不支持逻辑解码。
- 不支持PITR。
- 不支持发布订阅。
- 不支持回收站。
- 不支持段页式管理。
- 不支持极致RTO。
- 不支持并发更新同一行。
- 不支持主备页面和文件自动修复。
其他
- 不支持透明加密(TDE)。
- 列存表目前只支持rank和row_number两个函数(其他窗口函数会先转换成行存再处理)。
- 不支持增量物化视图。
- 不支持虚拟索引
- Delta表不支持索引。
使用指导
语法格式
CREATE TABLE table_name
(column_name data_type [, ... ])
[ WITH ( ORIENTATION = value) ];
参数说明
table_name
要创建的表名。
column_name
新表中要创建的字段名。
data_type
字段的数据类型。
ORIENTATION
指定表数据的存储方式,即行存方式、列存方式,该参数设置成功后就不再支持修改。
取值范围:
ROW,表示表的数据将以行式存储。
行存储适合于OLTP业务,适用于点查询或者增删操作较多的场景,目前使用Astore,Ustore作为行存储引擎。
COLUMN,表示表的数据将以列式存储。
列存储适合于数据仓库业务,此类型的表上会做大量的汇聚计算,且涉及的列操作较少,目前使用Cstore作为列存储引擎。
行存表
默认创建表的类型。数据按行进行存储,即一行数据是连续存储。适用于对数据需要经常更新的场景。不指定ORIENTATION参数时,表默认为行存表。
openGauss=# CREATE TABLE customer_t1
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
);
--删除表
openGauss=# DROP TABLE customer_t1;
列存表
数据按列进行存储,即一列所有数据是连续存储的。单列查询IO小,比行存表占用更少的存储空间。适合数据批量插入、更新较少和以查询为主统计分析类的场景。列存表不适合点查询。创建列存表时,需要指定ORIENTATION参数。
openGauss=# CREATE TABLE customer_t2
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
)
WITH (ORIENTATION = COLUMN);
--删除表
openGauss=# DROP TABLE customer_t2;
行存表和列存表的选择
更新频繁程度
数据如果频繁更新,选择行存表。
插入频繁程度
频繁的少量插入,选择行存表。一次插入大批量数据,选择列存表。
表的列数
表的列数很多,选择列存表。
查询的列数
如果每次查询时,只涉及了表的少数(<50%总列数)几个列,选择列存表。
压缩率
列存表比行存表压缩率高。但高压缩率会消耗更多的CPU资源。