HTAP 行列融合
可获得性
本特性自 openGauss 7.0.0-RC1 版本开始引入。
特性简介
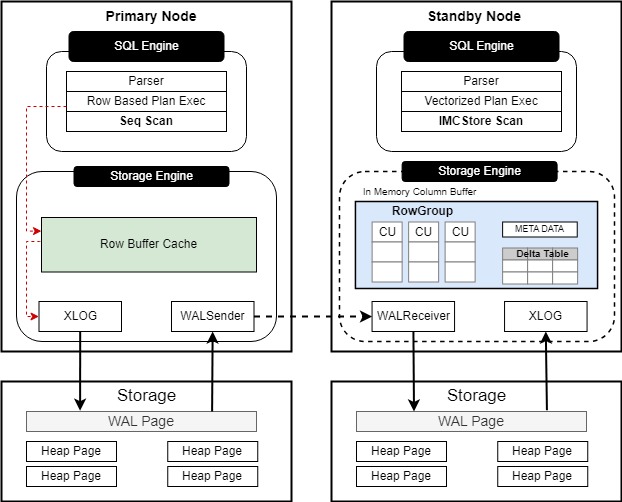
HTAP 行列融合特性在单机、主备场景下,通过节点的行列双格式内存模式,实现openGauss HTAP一体化数据库架构。 通过高效的行列转换技术方案,节点读取磁盘行存数据,生成列存储单元(Column Unit)存储至节点的列缓存中;支持节点通过代价估算生成列缓存查询计划,通过列存查询大幅提升复杂OLAP场景下的数据分析效率,使数据库同时具备较强的TP和AP能力。在主备场景下,列缓存数据均存储在备节点,通过日志读取回放,同步主节点在OLTP场景下大量的行数据变更,以维持列缓存数据的新鲜度。
客户价值
随着企业数字化变更深入,实时的高并发事务处理及复杂的数据整合、分析混合工作负载成为企业数据库的核心诉求。业务系统逐步通过HTAP(Hybrid Transactional/Analytical Processing)数据库的模式升级来响应新的业务场景,即通过同一套数据库内存系统,同时支持高效的事务处理(OLTP)和复杂查询(OLAP)。
openGauss 通过简单的指令设置,有效利用备节点可用内存空间进行行存数据的列缓存转换及存储(In-Memory-Column-Store)。考虑列存的查询优势,在数据量庞大,表结构复杂,而用户仅关注部分列数据的查询的场景下,行列转换后的列缓存可有效提升企业执行大型复杂OLAP数据分析的整体查询效率。
特性描述
openGauss主备集群场景下,支持备节点形成行列双格式内存形式。针对主节点的行级修改,备节点通过日志同步主节点修改,将对应修改写入增量表中。同时,备节点后台启动的同步线程,将增量表中存储的行存修改同步至列存缓存中。用户在备节点发起的OLAP大型数据分析请求,将先通过逻辑判断是否已有查询表的列缓存数据,并根据代价计算形成基于列缓存的查询计划。
行列数据转换:
用户在主节点发送针对表数据的行列转换请求,将通过网络通道将指令传输至备节点;备节点根据指令信息初始化增量表,并行读取行存数据,形成基础列存储单元(Column Unit),批量插入申请的列存内存中。
基于日志的行列数据同步:
在不影响主节点行存数据修改效率的同时,为了保障备节点列缓存数据的实时性,设计备节点基于日志读取回放行存修改,以增量表及后台同步线程的方式进行列缓存数据的更新。
支持列缓存的扫描查询:
新增In-Memory-CStore-Scan (IMCStore scan)列缓存查询算子,基于openGauss执行优化器及代价估算,生成包含列缓存查询算子的向量化执行计划。
特性增强
无。
特性约束
HTAP 行列融合的规格约束如下:
表:仅支持普通表的行列转换,临时表、系统表、Toast表、Unlogged表、列存表、外表暂不支持,主备场景下不支持段页式表的行列转换。
数据类型:参考列存表支持的数据类型。特别地:
- 不支持长度未知的数据类型,如:text、hll、cidr等类型。
- 不支持长度超过 8kb 的可变长度数据库类型,如:char(2500)、varchar(2500)。不建议转换较长长度的数据类型的列。
其他
- 当前仅在单数据库下支持行列转换。
- 轻量版 openGauss 不支持 HTAP 行列融合特性。
- 主备场景下,由主节点发起行列转换请求,所有备节点均执行行列转换,主节点不存储列缓存。
- 主备场景下,主节点引起的数据修改,在备节点通过列缓存查询存在一定延迟。
- 当前不支持重新行列转换,已经转换的表/分区需要先取消行列转换后,再重新行列转换。
- 转换分区表时,若指定某个分区行列转换,仅支持指定一级分区,若指定一级分区下存在二级分区,默认自动行列转换。
- 已行列转换的表,不支持 truncate 表、修改列名/列属性、增加/删除列、修改表压缩参数操作。特别地,已经转换的分区表,不支持新增、删除、交换、清空、分割、合并、移动、重命名操作。
- 对于间隔分区表,自动新增的分区,当前不会自动行列转换。
- 当前 DB 已转换的表,不支持 VACUUM FULL 操作。
主备场景下,需要修改主备节点的pg_hba.conf认证方式,以允许行列转换请求传输(这里的值取决于实际的网络配置以及用于连接的用户):
host all dbuser primary_ip/32 trust
host all dbuser standby_ip/32 trust
依赖关系
使用指导
HTAP 行列融合特性支持用户针对全表、表指定列、指定分区进行行列转换及清除已有列缓存操作。
对指定行表进行行列转换
转换方式1:全表转换
ALTER TABLE table_name IMCSTORED;转换方式2:表部分列转换
ALTER TABLE table_name IMCSTORED(column_name_list);转换方式3:对分区表的指定分区转换
ALTER TABLE table_name MODIFY PARTITION partition_name IMCSTORED;转换方式4:对分区表的指定分区的部分列转换,支持不同分区转换不同列
ALTER TABLE table_name MODIFY PARTITION partition_name IMCSTORED(column_name_list);
清除已转换的列缓存
- 清除方式1:对指定行表做全量列缓存清除
ALTER TABLE table_name UNIMCSTORED; - 清除方式2:对分区表的指定分区做列缓存清除
ALTER TABLE table_name MODIFY PARTITION partition_name UNIMCSTORED;
- 清除方式1:对指定行表做全量列缓存清除
参数说明
table_name
要转换的表名。
column_name_list
指定表中要行转列的字段名列表,如 (name, age)。
partition_name
要转换的分区名。
示例
对已创建的行存表进行行列转换。例如:
--创建普通表
openGauss=# CREATE TABLE test
(
id INT,
name VARCHAR2(40),
dept_id INT
);
CREATE TABLE
--对该表进行行列转换
openGauss=# ALTER TABLE test IMCSTORED;
ALTER TABLE
--查询该表,执行行存计划
openGauss=# EXPLAIN SELECT * FROM test;
QUERY PLAN
---------------------------------------------------------
Seq Scan on test (cost=0.00..16.01 rows=601 width=106)
(1 row)
--开启列存扫描计划
openGauss=# SET enable_imcsscan=on;
SET
--查询该表,执行列存计划
openGauss=# EXPLAIN SELECT * FROM test;
QUERY PLAN
--------------------------------------------------------------------
Row Adapter (cost=10.60..10.60 rows=601 width=106)
-> IMCStore Scan on test (cost=0.00..10.60 rows=601 width=106)
(2 rows)
--对该表清除列缓存
openGauss=# ALTER TABLE test UNIMCSTORED;
ALTER TABLE
--对该表部分列进行行列转换
openGauss=# ALTER TABLE test IMCSTORED(id);
ALTER TABLE
--创建分区表
openGauss=# CREATE TABLE test_partition
(
id INT,
name VARCHAR2(40),
dept_id INT,
age INT
) PARTITION BY RANGE(dept_id) SUBPARTITION BY RANGE (age)
(
PARTITION dept_id_p1 VALUES LESS THAN (5) (
SUBPARTITION age_sub_p1 VALUES LESS THAN (25),
SUBPARTITION age_sub_p2 VALUES LESS THAN (35),
SUBPARTITION age_sub_p3 VALUES LESS THAN (maxvalue)
),
PARTITION dept_id_p2 VALUES LESS THAN (maxvalue) (
SUBPARTITION age_sub_p4 VALUES LESS THAN (25),
SUBPARTITION age_sub_p5 VALUES LESS THAN (35),
SUBPARTITION age_sub_p6 VALUES LESS THAN (maxvalue)
)
);
CREATE TABLE
--对该表进行全量行列转换,即所有分区、所有列
openGauss=# ALTER TABLE test_partition IMCSTORED;
ALTER TABLE
--对该表清除列缓存
openGauss=# ALTER TABLE test_partition UNIMCSTORED;
ALTER TABLE
--对该表 dept_id_p1 分区的所有列进行行列转换
openGauss=# ALTER TABLE test_partition MODIFY PARTITION dept_id_p1 IMCSTORED;
ALTER TABLE
--对该表 dept_id_p1 分区清除列缓存
openGauss=# ALTER TABLE test_partition MODIFY PARTITION dept_id_p1 UNIMCSTORED;
ALTER TABLE
--对该表 dept_id_p1 分区的 id, name 列进行行列转换
openGauss=# ALTER TABLE test_partition MODIFY PARTITION dept_id_p1 IMCSTORED(id, name);
ALTER TABLE
--对该表 dept_id_p2 分区的 name, age 列进行行列转换
openGauss=# ALTER TABLE test_partition MODIFY PARTITION dept_id_p2 IMCSTORED(name, age);
ALTER TABLE
--开启列存扫描计划
openGauss=# SET enable_imcsscan=on;
SET
--查询该表 dept_id_p1 分区的 id, name 列, 执行列存计划
openGauss=# EXPLAIN SELECT id, name FROM test_partition PARTITION(dept_id_p1);
QUERY PLAN
-----------------------------------------------------------------------------------------------
Row Adapter (cost=5.58..5.58 rows=583 width=102)
-> Vector Partition Iterator (cost=0.00..5.58 rows=583 width=102)
Iterations: 1, Sub Iterations: 3
-> Partitioned IMCStore Scan on test_partition (cost=0.00..5.58 rows=583 width=102)
Selected Partitions: 1
Selected Subpartitions: ALL
(6 rows)
--查询该表 dept_id_p2 分区的 name, age 列, 执行列存计划
openGauss=# EXPLAIN SELECT name, age FROM test_partition PARTITION(dept_id_p2);
QUERY PLAN
-----------------------------------------------------------------------------------------------
Row Adapter (cost=5.58..5.58 rows=583 width=102)
-> Vector Partition Iterator (cost=0.00..5.58 rows=583 width=102)
Iterations: 1, Sub Iterations: 3
-> Partitioned IMCStore Scan on test_partition (cost=0.00..5.58 rows=583 width=102)
Selected Partitions: 2
Selected Subpartitions: ALL
(6 rows)
--查询整张表 id, name 列, dept_id_p2 未转换 id 列, 执行行存计划
openGauss=# EXPLAIN SELECT name, age FROM test_partition;
QUERY PLAN
-------------------------------------------------------------------------------------
Partition Iterator (cost=0.00..15.83 rows=583 width=102)
Iterations: 2, Sub Iterations: 6
-> Partitioned Seq Scan on test_partition (cost=0.00..15.83 rows=583 width=102)
Selected Partitions: 1..2
Selected Subpartitions: ALL
(5 rows)
--查询整张表 name 列, dept_id_p1、dept_id_p2 均转换 name 列, 因此执行列存计划
openGauss=# EXPLAIN SELECT name FROM test_partition;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Row Adapter (cost=10.58..10.58 rows=583 width=98)
-> Vector Partition Iterator (cost=0.00..10.58 rows=583 width=98)
Iterations: 2, Sub Iterations: 6
-> Partitioned IMCStore Scan on test_partition (cost=0.00..10.58 rows=583 width=98)
Selected Partitions: 1..2
Selected Subpartitions: ALL
(6 rows)