内存不足问题
问题现象
客户端或日志里出现错误:memory usage reach the max_dynamic_memory。
原因分析
出现内存不足可能因GUC参数max_process_memory值设置较小相关,该参数限制一个openGauss实例可用最大内存。
处理分析
通过工具gs_guc适当调整max_process_memory参数值。注意需重启实例生效。
定位方法
1、数据库内存不足时,正常端口连接会失败,此时连接内存不足节点的+1。
2、端口+1登录成功后查询总的内存使用视图:
select * from gs_total_memory_detail;
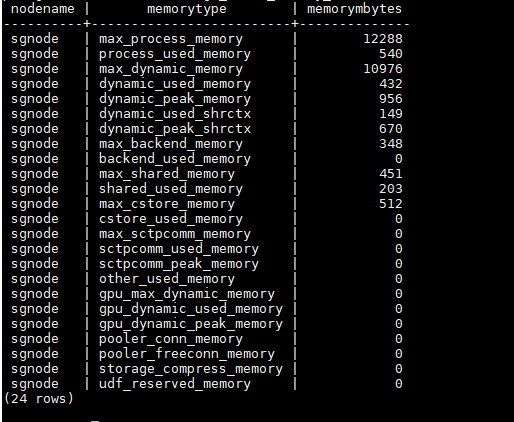
max_process_memory:guc参数设置
process_used_memory:进程实际使用的内存大小,同操作系统RES
max_dynamic_memory:MemoryContext能够使用的内存大小
dynamic_used_memory:MemoryContext实际使用的内存大小
dynamic_used_shrctx:SharedMemoryContext使用的内存大小
max_shared_memory:shared_buffers + 元数据
shared_used_memory:进程使用的共享内存大小
max_cstore_memory:cstore_buffers
other_used_memory:process_used_memory – dynamic_used_memory –shared_used_memory – cstore_used_memory
3、根据第2步中查出的内存使用情况进行如下分析:
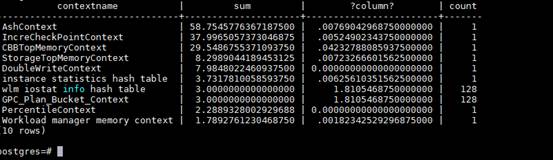
- 若dynamic_used_shrctx数据异常大,查询如下视图:gs_shared_memory_detail
select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from gs_shared_memory_detail group by contextname order by sum desc limit 10;
根据查出的内存context信息,使用内存最大的context可能存在内存泄漏。
- 若dynamic_used_memory数值较大,dynamic_used_shrctx数值很小,则查询如下视图:gs_session_memory_detail
select contextname, sum(totalsize)/1024/1024 sum, sum(freesize)/1024/1024, count(*) count from gs_session_memory_detail group by contextname order by sum desc limit 10;
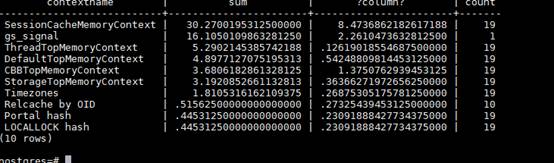
根据查出的内存context信息,看使用内存最大的context是否是常见的context,若不是则该context可能存在内存泄漏。
一般正常较大的context为:
SessionCacheMemoryContext,StorageTopMemoryContext
4、根据第3步中确认的可能存在内存泄漏的context,通过如下视图可直接查询该context上内存申请的详细信息;
gs_get_shared_memctx_detail(text) 描述:返回指定内存上下文上的内存申请的详细信息,包含每一处内存申请所在的文件、行号和大小(同一文件同一行大小会做累加)。只支持查询通过pg_shared_memory_detail视图查询出来的内存上下文,入参为内存上下文名称(即pg_shared_memory_detail返回结果的contextname列)。查询该函数必须具有sysadmin权限或者monitor admin权限。查询结果为如下三列:
名称 | 类型 | 描述 |
|---|---|---|
file | text | 申请内存所在文件的文件名。 |
line | int8 | 申请内存所在文件的代码行号。 |
size | int8 | 申请的内存大小,同一文件同一行多次申请会做累加。 |
注:该视图不支持release版本小型化场景。
描述:返回指定内存上下文上的内存申请的详细信息,包含每一处内存申请所在的文件、行号和大小(同一文件同一行大小会做累加)。仅在线程池模式下生效。且只支持查询通过pv_session_memory_context视图查询出来的内存上下文,入参为内存上下文名称(即pv_session_memory_context返回结果的contextname列)。查询该函数必须具有sysadmin权限或者monitor admin权限。查询结果为如下三列:
名称 | 类型 | 描述 |
|---|---|---|
file | text | 申请内存所在文件的文件名。 |
line | int8 | 申请内存所在文件的代码行号。 |
size | int8 | 申请的内存大小,同一文件同一行多次申请会做累加。 |
注:该视图仅在线程池模式下生效,且该视图不支持release版本小型化场景。
(1)在debug版本下,设置环境变量:
export MALLOC_CONF=prof:true,prof_final:false,prof_gdump:true,lg_prof_sample:20 。其中最后的20表示每2^20B(1MB)产生一个heap文件,该值可以调,但是调大以后,虽然heap文件会减少,但也会丢失一些内存申请信息。
(2)重启集群,如果是集群环境,需要kill om_monitor,并手动将om_monitor进程拉起。查看数据目录是否产生大量heap文件,如果产生,说明配置成功,否则需要重复上述步骤,直到产生heap文件。
(3)运行相关业务一段时间,取业务开始和最新的heap文件。
(4)使用jeprof处理heap文件,生成pdf。jeprof在代码仓binarylibs/${platForm}/jemalloc/debug/bin下可以获取,此外使用该二进制需要安装graphviz,可以通过yum install graphviz安装。
(5)生成pdf的命令:
全量:jeprof –show_bytes –pdf gaussdb *.heap > out.pdf
增量:jeprof –pdf gaussdb –base=start.heap end.heap > out.pdf
(6)根据生成的PDF分析结果:

可以看出该函数总共申请的内存大小,占系统总共申请内存大小的百分比等信息。