SMP适用场景与限制
背景信息
SMP特性通过算子并行来提升性能,同时会占用更多的系统资源,包括CPU、内存、I/O等等。本质上SMP是一种以资源换取时间的方式,在合适的场景以及资源充足的情况下,能够起到较好的性能提升效果;但是如果在不合适的场景下,或者资源不足的情况下,反而可能引起性能的劣化。SMP特性适用于分析类查询场景,这类场景的特点是单个查询时间较长、业务并发度低。通过SMP并行技术能够降低查询时延,提高系统吞吐性能。然而在事务类大并发业务场景下,由于单个查询本身的时延很短,使用多线程并行技术反而会增加查询时延,降低系统吞吐性能。
适用场景
支持并行的算子:计划中存在以下算子支持并行。
- Scan:支持行存普通表和行存分区表顺序扫描 、列存普通表和列存分区表顺序扫描。
- Join:HashJoin、NestLoop。
- Agg:HashAgg、SortAgg、PlainAgg、WindowAgg(只支持partition by,不支持order by)。
- Stream:Local Redistribute、Local Broadcast。
- 其他:Result、Subqueryscan、Unique、Material、Setop、Append、VectoRow。
SMP特有算子:为了实现并行,新增了并行线程间的数据交换Stream算子供SMP特性使用。这些新增的算子可以看做Stream算子的子类。
- Local Gather:实现实例内部并行线程的数据汇总。
- Local Redistribute:在实例内部各线程之间,按照分布键进行数据重分布。
- Local Broadcast:将数据广播到实例内部的每个线程。
- Local RoundRobin:在实例内部各线程之间实现数据轮询分发。
示例说明,以TPCH Q1的并行计划为例。
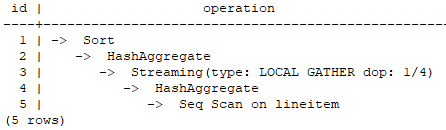
在这个计划中,实现了Scan以及HashAgg算子的并行,并新增了Local Gather数据交换算子。其中3号算子为Local Gather算子,上面标有的“dop: 1/4”表明该算子的发送端线程的并行度为4,而接受端线程的并行度为1,即下层的4号HashAggregate算子按照4并行度执行,而上层的1~2号算子按照串行执行,3号算子实现了实例内并行线程的数据汇总。
通过计划Stream算子上表明的dop信息即可看出各个算子的并行情况。
非适用场景
- 索引扫描不支持并行执行。
- MergeJoin不支持并行执行。
- WindowAgg order by不支持并行执行。
- cursor不支持并行执行。
- 存储过程和函数内的查询不支持并行执行。
- 不支持子查询subplan和initplan的并行,以及包含子查询的算子的并行。
- 查询语句中带有median操作的查询不支持并行执行。
- 带全局临时表的查询不支持并行执行。
- 物化视图的更新不支持并行执行。
意见反馈