UNION,CASE和相关构造
SQL UNION构造必须把那些可能不太相似的类型匹配起来成为一个结果集。解析算法分别应用于联合查询的每个输出字段。INTERSECT和EXCEPT构造对不相同的类型使用和UNION相同的算法进行解析。CASE、ARRAY、VALUES、GREATEST和LEAST构造也使用同样的算法匹配它的部件表达式并且选择一个结果数据类型。
UNION,CASE和相关构造解析
如果所有输入都是相同的类型,并且不是unknown类型,那么解析成这种类型。
如果所有输入都是unknown类型则解析成text类型(字符串类型范畴的首选类型)。否则,忽略unknown输入。
如果输入不属于同一个类型范畴,失败。(unknown类型除外)
如果输入类型是同一个类型范畴,则选择该类型范畴的首选类型。(例外:union操作会选择第一个分支的类型作为所选类型。)
 说明:
说明:系统表pg_type中typcategory表示数据类型范畴,typispreferred表示是否是typcategory分类中的首选类型。
把所有输入转换为所选的类型(对于字符串保持原有长度)。如果从给定的输入到所选的类型没有隐式转换则失败。
若输入中含json、txid_snapshot、sys_refcursor或几何类型,则不能进行union。
对于case和coalesce,在TD兼容模式下的处理
- 如果所有输入都是相同的类型,并且不是unknown类型,那么解析成这种类型。
- 如果所有输入都是unknown类型则解析成text类型。
- 如果输入字符串(包括unknown,unknown当text来处理)和数字类型,那么解析成字符串类型,如果是其他不同的类型范畴,则报错。
- 如果输入类型是同一个类型范畴,则选择该类型的优先级较高的类型。
- 把所有输入转换为所选的类型。如果从给定的输入到所选的类型没有隐式转换则失败。
对于case,在ORA兼容模式下的处理
decode(expr, search1, result1, search2, result2, …, defresult),也即 case expr when search1 then result1 when search2 then result2 else defresult end; 在ORA兼容模式下的处理,将整个表达式最终的返回值类型定为result1的数据类型,或者与result1同类型范畴的更高精度的数据类型。(例如,numeric与int同属数值类型范畴,但numeric比int精度要高,具有更高优先级)
- 将result1的数据类型置为最终的返回值类型preferType,其所属类型范畴为preferCategory。
- 依次考虑result2、result3直至defresult的数据类型。如果其类型范畴也是preferCategory,即与result1具有相同的类型范畴,则判断其精度(优先级)是否高于preferType,如果高于,则将preferType更新为更高精度的数据类型;如果其类型范畴不是preferCategory,则判断其数据类型是否可以隐式转换为preferType,不可以则报错。
- 将最终preferType记录的数据类型作为整个表达式最终的返回值类型;表达式的结果向此类型进行隐式转换。
注1:
为了兼容一种特殊情况,即表示了超大数字的字符类型向数值类型转换的情况,例如select decode(1, 2, 2, “53465465676465454657567678676”),大数超过了bigint、double等的表示范围。所以,当result1的类型范畴为数值类型时,将返回值的类型直接置为numeric,以兼容此种特殊情况。
注2:
数值类型的优先级排序:numeric>float8>float4>int8>int4>int2>int1
字符类型的优先级排序:text>varchar=nvarchar2>bpchar>char
日期类型的优先级排序:timestamptz>timestamp>smalldatetime>date>abstime>timetz>time
日期跨度类型的优先级排序:interval>tinterval>reltime
注3:
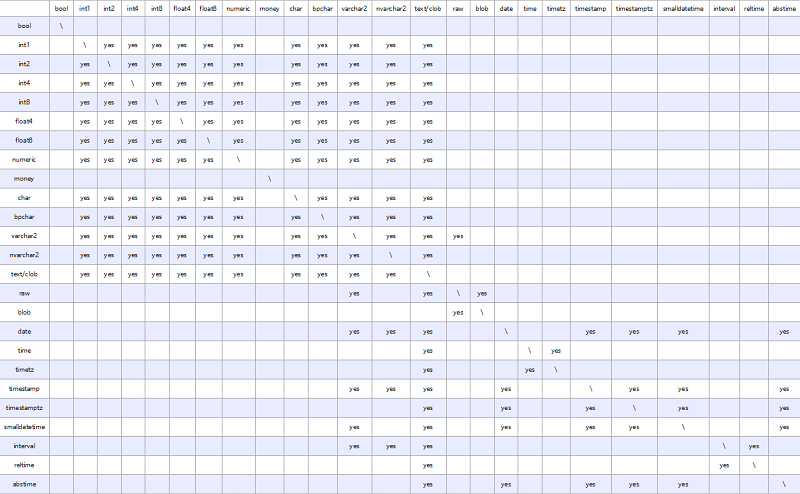
ORA兼容模式,开启 set sql_beta_feature = 'a_style_coerce'; 参数的情况下,所支持的隐式类型转换见下图,\代表不需要转换,yes表示支持,空白表示不支持:
示例
示例1:Union中的待定类型解析。这里,unknown类型文本'b'将被解析成text类型。
openGauss=# SELECT text 'a' AS "text" UNION SELECT 'b';
text
------
a
b
(2 rows)
示例2:简单Union中的类型解析。文本1.2的类型为numeric,而且integer类型的1可以隐含地转换为numeric,因此使用这个类型。
openGauss=# SELECT 1.2 AS "numeric" UNION SELECT 1;
numeric
---------
1
1.2
(2 rows)
示例3:转置Union中的类型解析。这里,因为类型real不能被隐含转换成integer,但是integer可以隐含转换成real,那么联合的结果类型将是real。
openGauss=# SELECT 1 AS "real" UNION SELECT CAST('2.2' AS REAL);
real
------
1
2.2
(2 rows)
示例4:TD模式下,coalesce参数输入int和varchar类型,那么解析成varchar类型。A模式下会报错。
--在A模式下,创建A兼容模式的数据库a_1。
openGauss=# CREATE DATABASE a_1 dbcompatibility = 'A';
--切换数据库为a_1。
openGauss=# \c a_1
--创建表t1。
a_1=# CREATE TABLE t1(a int, b varchar(10));
--查看coalesce参数输入int和varchar类型的查询语句的执行计划。
a_1=# EXPLAIN SELECT coalesce(a, b) FROM t1;
ERROR: COALESCE types integer and character varying cannot be matched
LINE 1: EXPLAIN SELECT coalesce(a, b) FROM t1;
^
CONTEXT: referenced column: coalesce
--删除表。
a_1=# DROP TABLE t1;
--切换数据库为openGauss。
a_1=# \c openGauss
--在TD模式下,创建TD兼容模式的数据库td_1。
openGauss=# CREATE DATABASE td_1 dbcompatibility = 'C';
--切换数据库为td_1。
openGauss=# \c td_1
--创建表t2。
td_1=# CREATE TABLE t2(a int, b varchar(10));
--查看coalesce参数输入int和varchar类型的查询语句的执行计划。
td_1=# EXPLAIN VERBOSE select coalesce(a, b) from t2;
QUERY PLAN
---------------------------------------------------------------------------------------
Data Node Scan (cost=0.00..0.00 rows=0 width=0)
Output: (COALESCE((t2.a)::character varying, t2.b))
Node/s: All dbnodes
Remote query: SELECT COALESCE(a::character varying, b) AS "coalesce" FROM public.t2
(4 rows)
--删除表。
td_1=# DROP TABLE t2;
--切换数据库为openGauss。
td_1=# \c openGauss
--删除A和TD模式的数据库。
openGauss=# DROP DATABASE a_1;
openGauss=# DROP DATABASE td_1;
示例5:ORA模式下,将整个表达式最终的返回值类型定为result1的数据类型,或者与result1同类型范畴的更高精度的数据类型。
--在ORA模式下,创建ORA兼容模式的数据库ora_1。
openGauss=# CREATE DATABASE ora_1 dbcompatibility = 'A';
--切换数据库为ora_1。
openGauss=# \c ora_1
--开启Decode兼容性参数。
set sql_beta_feature='a_style_coerce';
--创建表t1。
ora_1=# CREATE TABLE t1(c_int int, c_float8 float8, c_char char(10), c_text text, c_date date);
--插入数据。
ora_1=# INSERT INTO t1 VALUES(1, 2, '3', '4', date '12-10-2010');
--result1类型为char,defresult类型为text,text精度更高,返回值的类型由char更新为text。
ora_1=# SELECT decode(1, 2, c_char, c_text) AS result, pg_typeof(result) FROM t1;
result | pg_typeof
--------+-----------
4 | text
(1 row)
--result1类型为int,属于数值类型范畴,返回值的类型置为numeric。
ora_1=# SELECT decode(1, 2, c_int, c_float8) AS result, pg_typeof(result) FROM t1;
result | pg_typeof
--------+-----------
2 | numeric
(1 row)
--不存在defresult数据类型向result1数据类型之间的隐式转换,报错处理。
ora_1=# SELECT decode(1, 2, c_int, c_date) FROM t1;
ERROR: CASE types integer and timestamp without time zone cannot be matched
LINE 1: SELECT decode(1, 2, c_int, c_date) FROM t1;
^
CONTEXT: referenced column: c_date
--关闭Decode兼容性参数。
set sql_beta_feature='none';
--删除表。
ora_1=# DROP TABLE t1;
DROP TABLE
--切换数据库为postgres。
ora_1=# \c postgres
--删除ORA模式的数据库。
openGauss=# DROP DATABASE ora_1;
DROP DATABASE