Planning a Storage Model
openGauss supports hybrid row storage and column storage. Each storage model applies to specific scenarios. Select an appropriate model when creating a table. Generally, openGauss is used for transactional processing databases. By default, row storage is used. Column storage is used only when complex queries in large data volume are performed.
Row-store stores tables to disk partitions by row, and column-store stores tables to disk partitions by column. By default, a row-store table is created. For details about differences between row storage and column storage, see Figure 1.
Figure 1 Differences between row storage and column storage
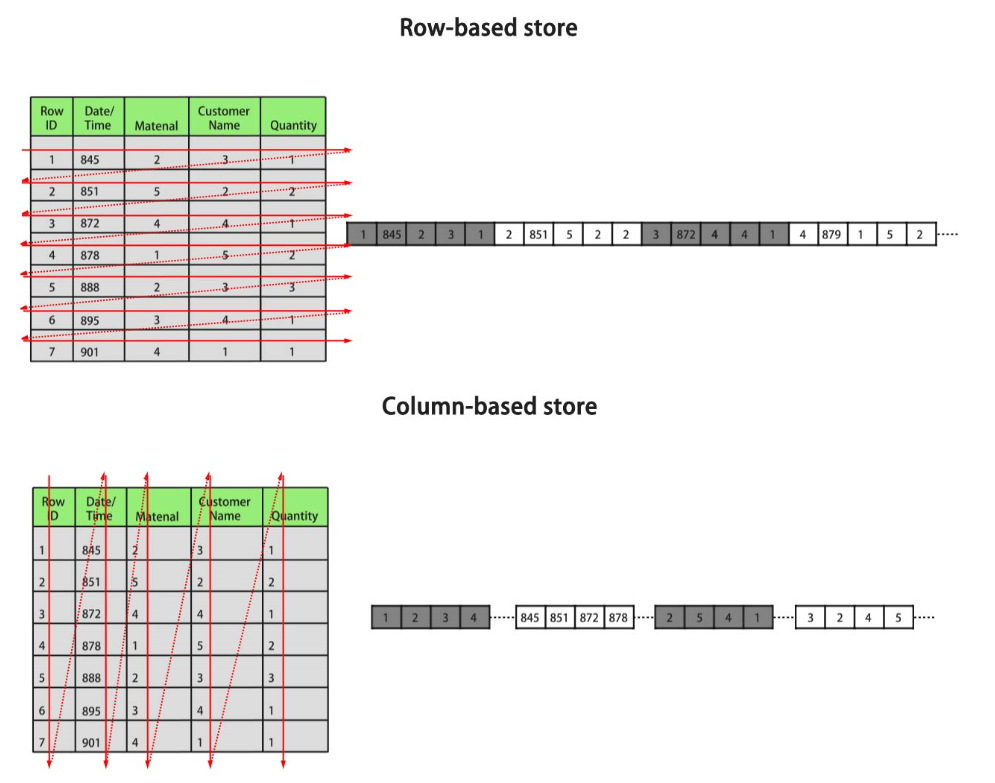
In the preceding figure, the upper left part is a row-store table, and the upper right part shows how the row-store table is stored on a disk; the lower left part is a column-store table, and the lower right part shows how the column-store table is stored on a disk.
Both storage models have benefits and drawbacks.
Generally, if a table contains many columns (called a wide table) and its query involves only a few columns, column storage is recommended. Row storage is recommended if a table contains only a few columns and a query involves most of the fields.
Row-Store Tables
Row-store tables are created by default. In a row-store table, data is stored by row, that is, data in each row is stored continuously. Therefore, this storage model applies to scenarios where data needs to be updated frequently.
postgres=# CREATE TABLE customer_t1
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
);
--Delete the table.
postgres=# DROP TABLE customer_t1;
Column-Store Tables
In a column-store table, data is stored by column, that is, data in each column is stored continuously. The I/O of data query in a single column is small, and column-store tables occupy less storage space than row-store tables. This storage model applies to scenarios where data is inserted in batches, less updated, and queried for statistical analysis. A column-store table cannot be used for point queries.
postgres=# CREATE TABLE customer_t2
(
state_ID CHAR(2),
state_NAME VARCHAR2(40),
area_ID NUMBER
)
WITH (ORIENTATION = COLUMN);
--Delete the table.
postgres=# DROP TABLE customer_t2;
Selecting a Storage Model
Update frequency
If data is frequently updated, use a row-store table.
Data insertion frequency
If a small amount of data is frequently inserted each time, use a row-store table. If a large amount of data is inserted at a time, use a column-store table.
Number of columns
If a table is to contain many columns, use a column-store table.
Number of columns to be queried
If only a small number of columns (less than 50% of the total) is queried each time, use a column-store table.
Compression ratio
The compression ratio of a column-store table is higher than that of a row-store table. High compression ratio consumes more CPU resources.