Description
As described in Overview, EXPLAIN displays the execution plan, but will not actually run SQL statements. EXPLAIN ANALYZE and EXPLAIN PERFORMANCE both will actually run SQL statements and return the execution information. This section describes the execution plan and execution information in detail.
Execution Plans
The following SQL statement is used as an example:
SELECT * FROM t1, t2 WHERE t1.c1 = t2.c2;
Run the EXPLAIN command and the output is as follows:
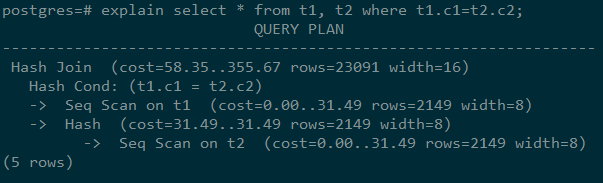
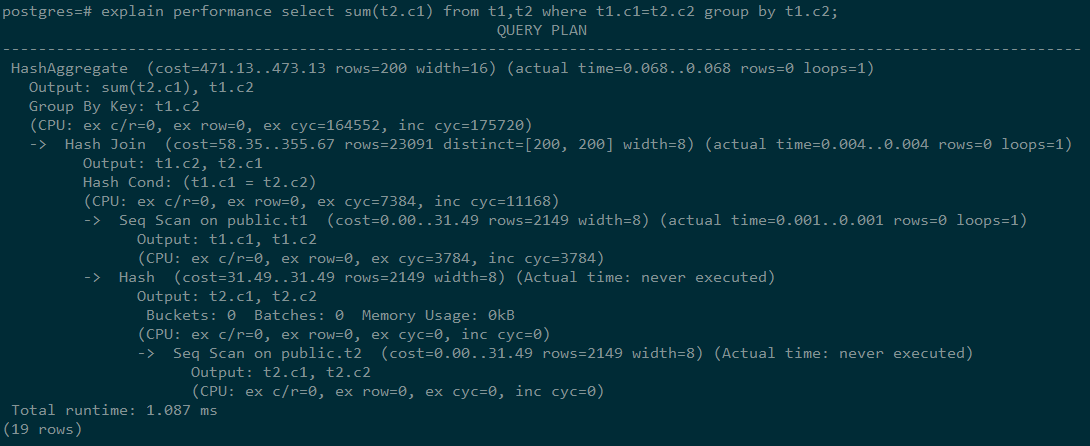
Interpretation of the execution plan level (vertical):
Layer 1: Seq Scan on t2
The table scan operator scans the table t2 using Seq Scan. At this layer, data in the table t2 is read from a buffer or disk, and then transferred to the upper-layer node for calculation.
Layer 2: Hash
Hash operator. It is used to calculate the hash value of the operator transferred from the lower layer for subsequent hash join operations.
Layer 3: Seq Scan on t1
The table scan operator scans the table t1 using Seq Scan. At this layer, data in the table t1 is read from a buffer or disk, and then transferred to the upper-layer node for hash join calculation.
Layer 4: Hash Join
Join operator. It is used to join data in the t1 and t2 tables using the hash join method and output the result data.
Keywords in the execution plan:
Table access modes
Seq Scan
Scans all rows of the table in sequence.
Index Scan
The optimizer uses a two-step plan: the child plan node visits an index to find the locations of rows matching the index condition, and then the upper plan node actually fetches those rows from the table itself. Fetching rows separately is much more expensive than reading them sequentially, but because not all pages of the table have to be visited, this is still cheaper than a sequential scan. The upper-layer planning node sorts index-identified rows based on their physical locations before reading them. This minimizes the independent capturing overhead.
If there are separate indexes on multiple columns referenced in WHERE, the optimizer might choose to use an AND or OR combination of the indexes. However, this requires the visiting of both indexes, so it is not necessarily a win compared to using just one index and treating the other condition as a filter.
The following Index scans featured with different sorting mechanisms are involved:
Bitmap Index Scan
Fetches data pages using a bitmap.
Index Scan using index_name
Fetches table rows in index order, which makes them even more expensive to read. However, there are so few rows that the extra cost of sorting the row locations is unnecessary. This plan type is used mainly for queries fetching just a single row and queries having an ORDER BY condition that matches the index order, because no extra sorting step is needed to satisfy ORDER BY.
Table connection modes
Nested Loop
A nested loop is used for queries that have a smaller data set connected. In a nested loop join, the foreign table drives the internal table and each row returned from the foreign table should have a matching row in the internal table. The returned result set of all queries should be less than 10,000. The table that returns a smaller subset will work as a foreign table, and indexes are recommended for connection columns of the internal table.
(Sonic) Hash Join
A hash join is used for large tables. The optimizer uses a hash join, in which rows of one table are entered into an in-memory hash table, after which the other table is scanned and the hash table is probed for matches to each row. Sonic and non-Sonic hash joins differ in their hash table structures, which do not affect the execution result set.
Merge Join
In most cases, the execution performance of a merge join is lower than that of a hash join. However, if the source data has been pre-sorted and no more sorting is needed during the merge join, its performance excels.
Operators
sort
Sorts the result set.
filter
The EXPLAIN output shows the WHERE clause being applied as a Filter condition attached to the Seq Scan plan node. This means that the plan node checks the condition for each row it scans, and returns only the ones that meet the condition. The estimated number of output rows has been reduced because of the WHERE clause. However, the scan will still have to visit all 10,000 rows, as a result, the cost is not decreased. It increases a bit (by 10,000 x cpu_operator_cost) to reflect the extra CPU time spent on checking the WHERE condition.
LIMIT
Limits the number of output execution results. If a LIMIT condition is added, not all rows are retrieved.
Execution Information
The following SQL statement is used as an example:
select sum(t2.c1) from t1,t2 where t1.c1=t2.c2 group by t1.c2;
The output of running EXPLAIN PERFORMANCE is as follows: